企業専門QAシステムは、企業内部または顧客対応の現場で利用される「知能型Q&Aシステム」であり、企業の業務・製品・制度・プロセスなどに関する専門的な質問に回答するために設計された仕組みです。
このシステムは、営業・技術・製品など複数の業務領域を統合する必要があるため、企業内部の大量文書、FAQ、ERP、CRM、ナレッジベースなどの構造化・非構造化データを扱います。また、テキスト・音声・画像など多様な入力形式への対応と、新しい知識の継続的な追加および自動更新も重要になります。
多くの人はこうした専用システムの構築は複雑でコストも高いと考えがちですが、実は「OpenClaw Ultra」を活用することで比較的簡単に構築できます。
OpenClaw Ultra のインストール・デプロイおよび API KEY の取得と使用
OpenClaw Ultra はワンクリックデプロイに対応しており、依存関係の手動インストールや追加の実行環境設定は不要。1回のデプロイでシステム初期化が完了し、すぐに利用を開始できる。
利用を開始する場合は、以下のダウンロードページにアクセスする:
https://openclaw.aiondesktop.com/?lang=ja
また、詳しい操作方法や利用ガイドについては、公式チュートリアルをご参照ください:
https://openclaw.aiondesktop.com/tutorials/ja/

企業専門QAシステムのアーキテクチャ設計
以下の構成で企業専門QAシステムを設計します。
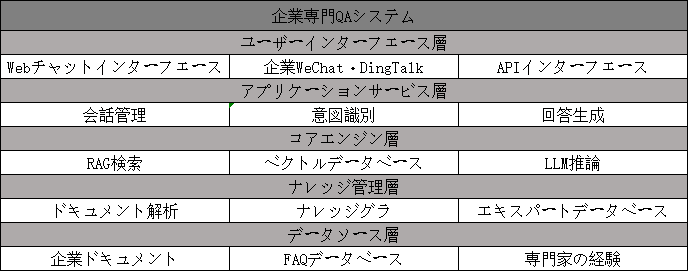
コアコンポーネントの構築
ナレッジベースの構築
ナレッジベースは企業QAシステムの「大脳」にあたり、その品質がシステム全体の成否を決定します。

注意事項:
- 高頻度質問から着手し、複数チャネルからデータ収集
- (既存FAQ、スプレッドシート、製品マニュアル、カスタマーサポート履歴、専門家インタビュー、ベテラン社員の知見、企業意思決定情報など)
- 古い情報の削除、重複データの排除、誤情報の修正
- 用語の統一、コンテキスト補完、フォーマット標準化(タイトル・段落・リスト形式)
ナレッジベース構造
├── 製品知識/
│ ├── 製品A/
│ │ ├── 概要.md
│ │ ├── 機能説明.md
│ │ ├── 技術仕様.md
│ │ └── FAQ.md
│ └── 製品B/
├── 技術サポート/
│ ├── インストール・デプロイ/
│ ├── 障害対応/
│ └── APIドキュメント/
├── 業務プロセス/
│ ├── 営業プロセス/
│ ├── アフターサービス/
│ └── 返品・交換ポリシー/
└── 社内制度/
├── 人事制度/
└── 財務制度/
システム機能モジュール
専用企業QAシステムのコア機能は以下の通りです:
- マルチターン会話コンテキスト管理
- 質問意図の識別およびルーティング
- 回答の信頼度スコアリング
- 未知質問の有人対応切替
- フィードバック学習ループ
- 権限レベル別アクセス制御
- 監査ログおよびコンプライアンス対応
システム実装ステップ
フェーズ1:ナレッジ準備(2〜4週間)
- 企業文書・FAQ・専門知識の収集
- データクリーニングおよび標準化
- ナレッジ分割およびベクトル化
- テスト用質問セット構築
フェーズ2:システム構築(3〜5週間)
- ベクトルデータベース導入(Milvus / Qdrant / Weaviate)
- RAG検索パイプライン構築(マルチリコール・リランキング・引用トレーサビリティ)
- LLMモデル接続(Qwen3.5 / GLM-4 / DeepSeekなど)
- 対話管理システム開発
ベクトルデータベースデプロイ
ベクトルデータベースはRAGシステムの「記憶中枢」であり、ベクトル化された知識を効率的に保存・検索します。以下に主要なデプロイ方法を示します。

RAG検索パイプライン構成
「OpenClaw」は専用RAGシステムではありませんが、カスタムSkillおよびexecツールを活用することで完全なRAG機能を統合できます。適切な指示を設定することで構築可能です。
LLMモデルの利用
企業QAシステムにおいてLLMはRAGパイプラインの中核であり、検索結果をもとに最終回答を生成します(APIキー必要)。
OpenClawでは以下のように設定できます:
「あなたは企業向け専門QAアシスタントです。企業内部の専門質問に対して正確かつ明確に回答してください。」
さらに以下のルールを厳守します:
- 提供された文書のみに基づいて回答する
- 文書に存在しない場合は「現時点の資料では回答できません」と明示する
- 推測や創作情報は禁止
- 構造化された回答(見出し・リスト)
- 質問と同じ言語で回答
- 重要情報は冒頭に記載
- すべての回答に参照情報を付与
対話管理
対話管理はユーザー体験を左右する重要な要素です。マルチターン対話、セッション状態管理、コンテキスト保持などを含む設計が必要です。
完全な対話フロー例:
- ユーザーが質問を入力
- システムが意図を解析(意図識別)
- 関連するナレッジをRAGで検索
- ベクトルデータベースから候補を取得
- LLMが最終回答を生成
- ユーザーに回答を返却
- フィードバックを収集し改善に反映
この一連の流れによって、継続的で文脈を保持した自然な対話体験を実現します。
継続運用と最適化
- ユーザーフィードバック収集
- 回答品質評価
- ナレッジベース継続更新
- モデルファインチューニング
初期コスト見積
├─ ハードウェア / クラウドリソース
├─ モデルAPI(利用量に応じた年間費用)
├─ 開発人員:2〜3名 × 2〜3ヶ月
└─ ナレッジ整理:1〜2名(継続)
デプロイ方式
- プライベートデプロイ(データセキュリティ重視)
- ハイブリッドクラウド構成
成功要因
- ナレッジベースの定期更新
- Q&Aログ分析
- フィードバックによる改善
- マルチリコール+リランキングによる検索精度向上
- 運用プロセスの最適化
- 追加機能(運用後)
- デプロイ後はユーザー体験向上のため、以下を追加可能です:
マルチターン会話対応
権限管理システム
監査ログ機能